
I gotta tell you: CQRS doesn't imply Event Sourcing
Jan 27, 2024 • Mauro Servienti • Reading time: • Improve
this post • Changelog • Reviewed by: ![]()
For the N th time (where N > 4), I read a post describing the beauty and benefits of Command Query Responsibility Segregation (CQRS). As on many other occasions, it made me cringe: The post assumed that Event Sourcing (ES) is part of the equation.
I’m sorry, it’s not.
Please repeat after me: CQRS doesn’t need Event Sourcing. We can implement a CQRS-based architecture without persisting data using events and projections.
It’s like it was engraved in stone that the only way to use the CQRS architectural style is by projecting data into read models, and when that’s the topic, the source for those read models is an event store. That leads to the conclusion that “oh, I for sure need to persist data using event sourcing.”
CQRS is all about interfaces. It has nothing to do with the persistence layer or the storage technology. Event Sourcing is all about persistence. It’s one of the ways we can choose to persist data.
I believe the confusion comes from how we interpret the word “interface.” And I know the language we use has limitations.
In this case, however, the confusion starts from needing to pay more attention to what an architectural style or system architecture is. People read Command Query Responsibility Segregation and immediately connect to storage and, from there, to databases—my hunch is that “query” is the tricky word. From databases, it’s somewhat natural to state that if there must be segregation between commands and queries, they must use different data stores. And voila, if the need is for different storage, what’s better than this event-sourcing technology that (apparently) gives me both in one go? Two pigeons with one stone.
From there, jumping to horrendous models like the following is tremendously easy:
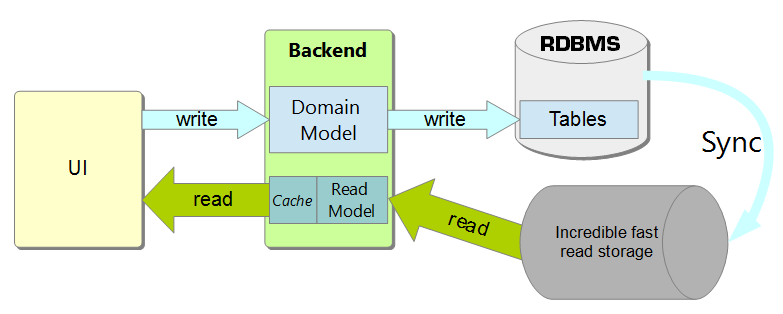
I’m not saying that implementing a CQRS architecture using ES is wrong. I’m saying that it’s not mandatory—like too many times is presented—and if done without using the right tools, it comes with more downsides than benefits.
What’s the problem with Event Sourcing?
Technically speaking, there’s none. Hold on; one could argue that the above result is an abomination. I’m sure it’s not that frequent, though. Right?
One of the downsides, depending on the chosen design, is eventual consistency. I know that we’re surrounded by it, but at the same time, we should not be artificially creating it where it’s not necessary.
Teams could embrace CQRS as their approach to designing most, if not all, the query/command interactions; they could even elect CQRS as a top-level architecture or a general approach to system design. If that’s the case, and the implementation requires event sourcing, they’re also bringing ES everywhere in the system, even where it makes no sense or does more harm than good.
Back to basics
Let’s take a step back to understand the goal here. As software developers, we should strive to design maintainable and evolvable software. Unless what we’re releasing will never be touched again, sooner or later, we’ll be faced with requests to fix something that doesn’t work as planned or to evolve or add features. If the overall design is terrible, it’ll be difficult to fulfill those requests.
CQRS, as an instance of the Single Responsibility Principle (SRP), greatly helps design more straightforward software to maintain and evolve. And that’s it. It doesn’t dictate that we need to use event sourcing, employ different databases, or use messages and queues to propagate changes from the write models to the read ones.
CQRS is about drawing a thick line separating the system’s writing and reading pipes. It tells us not to mix write and read models but to keep them well isolated because they have different purposes.
And in practice?
Translating the presented principle in practice means, for example, that we should not be issuing SQL queries directly to a table. Instead, we could use stored procedures to write data (commands) and views to read data (queries).
If, in our codebase, we use an ORM, Entity Framework, for example, we could have different data contexts and different models for the command and query parts of the system. At this point, we might realize that the query-related models and data contexts are always read-only, and Dapper is a better lightweight alternative to Entity Framework for the queries.
If the system exposes API endpoints, querying endpoints should be separated from write endpoints. Or better yet, clients use HTTP endpoints to read data (queries), and they use queues and messages to request changes (commands).
In all the presented examples, and in the many more we could think about, the stress is not on the technology—that’s only supporting the example. It’s clearly on differentiating queries and commands.
Conclusion
Carefully understanding the differences between an architectural style and a persistence tactic is critical to not mixing apples and oranges where and when it doesn’t make sense. As discussed, CQRS doesn’t imply Event Sourcing. They are designed to address different concerns. Sometimes, we can use them in conjunction. At the same time, we also want to design systems so that we can choose when and where to use them.